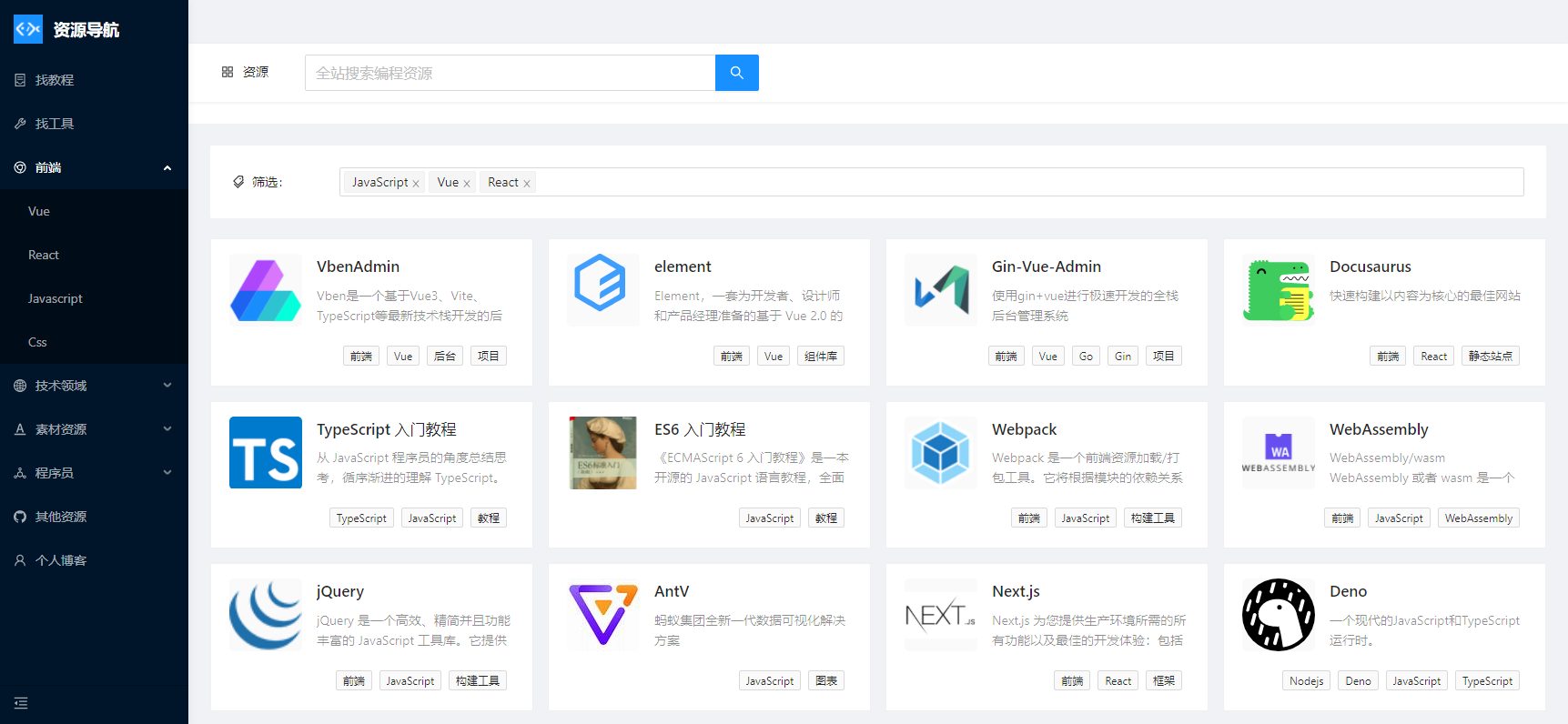
为什么要写这个
无意间刷到一个网站编程导航 - 发现优质编程资源 (code-nav.cn)
当时我学习的时候,也是有着这样类似的站点,才让我了解到一些未曾听闻过的优质资源,所以才萌生出编写类似资源导航的一个功能,记录下自己用过见过的一些工具,框架,顺便分享一波,不过我原本是考虑内置到个人博客上,而不是新建一个站点,但是上面的这个网站部分开源,并且基于 React + Ant Design Pro,正好我最新在学习该技术,于是就成为了我的一个练手项目,二话不说,直接 clone 了该仓库便开始了阅读源码。
注: 资源数据首次加载采用了随机排序,资源不分先后顺序。
思路分析
首先该项目的后端采用的是腾讯云的云开发,这里简单介绍一些云开发,本质上和正常开发没什么区别,都是服务端编写接口逻辑,客户端调用接口,主要的特点有如下几个
- 无需管理服务器、数据库等等 传统的后端开发都需要另外搭建一台服务器,配置一堆相关设置,然后他人通过 ip 加端口来进行调用,所以就免不了部署这一门槛了,而使用云开发就无需考虑这些因素,只需要编写对应的业务逻辑便可,也是常说的无服务架构
- 原生微信服务集成 腾讯云云开发可以直接接入微信用户数据,如果是小程序或公众号开发,接入将会特别方便
- 开发简单高效 开发简单,不要求特定的框架和依赖,只需要关注业务逻辑便可
- 成本更低 云开发一般都是按量使用,同时还会提供一定的免费额度(初次使用有 1 年额外的免费额度),相比购买一台服务器甚至专属的云数据库而言,很多情况下都会存在资源剩余的情况。
- 运维省事 每个云函数都是单独运行、单独部署、单独伸缩,用户上传代码后即可自动部署,免除单体式应用部署升级难的问题。
正好呢我又没接触过云开发,于是花了一个晚上的时间官方文档给过了一遍,理清如何发布与调用即可。
但是在该项目我并不打算使用云开发,为啥呢,我是打算写成纯静态的页面,资源更新的频率又不高,并且无需登录鉴权,所以后端服务基本用不上。于是把有关用户与数据交互的地方全部都给置成本地了。(也许后续会弄成需要登录的)
更改代码
定义分类文件
项目预先采用的是 Mock 数据,于是我吧 Mock 数据,替换成了真实数据,然后采用 Nodejs 模块导入的方式,将所要展示的资源导入进去,像这样
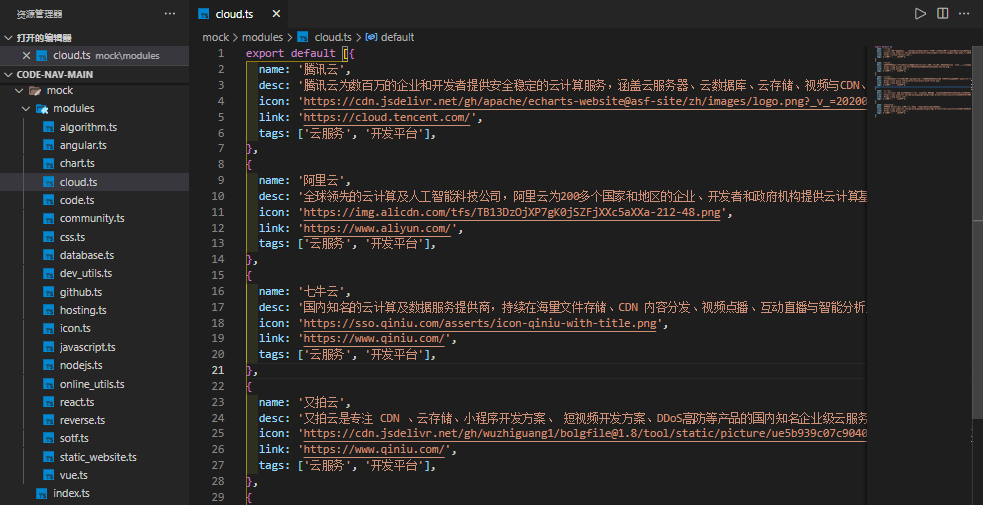
标注名称、简介、logo、链接、标签这些元素后,然后根据源码中自带的列表案例,进行样式微调整即可。
不过这里定义太多文件,就需要频繁的导入,于是我使用了 Nodejs 中require.context将指定目录 modules 中的所有文件自动导入,相关代码如下
const modulesFiles = require.context('./modules', true, /\.ts$/)
let allData: any[] = []
modulesFiles.keys().forEach((modulePath) => {
const value = modulesFiles(modulePath)
let data = value.default
if (!data) return
allData.push(...value.default)
})
这样每次在相应目录下定义完文件,就会将模块自动导入。
定义数据
名字和简介都还比较好解决,基本上官方文档都会一个简短的案例,可以直接拷贝过来,但令我头疼的是分类和标签,有的时候一个资源可以归分为好几个类别,像一些属于 Nodejs 的,但有些有属于 JavaScript 的,比如 Webpack,EsLint,Jest,就很抉择,再比如框架的话又细分为好几种,要标注为前端框架,后端框架,就很头疼。
一开始分类的时候没规划好,想到啥就从收藏夹中找对应的资源,开始填写,有时候写着写着,都不记得已经写过的东西
其次就是图片,有些官方未提供 favicon 文件,或者是图片尺寸太小,就只好从首页获取。但首页的图片并非是一个 url 资源,有可能是 Base64 编码的图片,或者是 Svg 格式的,Base64 的话还好,直接复制浏览器便能自动解码,反倒是内嵌的 Svg 标签,没办法,只好截图将这些图片上传到图床,然后在通过外链进行访问了。
整理资源
然后就是开始整理资源,写数据,很枯燥,比写代码还要枯燥,有一时间内,我甚至开始羡慕起写代码了。
目前大致把我遇到过的给记录一下,前前后后整理了有 150 个左右资源,后续是肯定还会补充新的资源点(开始点技能了),主要我的技术栈都是 JavaScript 和 Nodejs,所以大部分资源都是围绕这些,所以导航中可能会遇到些如果有我未提及到的,那大概率我没了解过或是没必要写的。
资源主要来源:除了我自己之前整理过外,还借鉴了如下几个资源点。
一些问题
非搜索引擎式搜索
由于网站内的资源数据都是纯静态的,在搜索上我是直接采用了 JavaScript 中数组的 includes 来进行判断是否存在的,并未使用分词这些,(如果数据都存放至 Elasticsearch 上,这些都不是事),所以搜索并不能像搜索引擎那样进行分词搜索。(就连大小写都不区分的那种)
标签不可自定义
同样的,标签也是会有这个问题,并且我并未将全部标签内置,也就是说,部分标签是无法进行筛选了,主流的肯定是预先设置好了的。同时也不支持自定义标签搜索。
未含基础知识点
例如基本的计算机系统,数据结构,算法等等这些我并没有写入,至于为什么,这就不细说了。(我自己都不记得我到底学没学过这些),后续如果有需要的话,应该是会补上的。
最后
从 clone 到发布花了差不多有一周左右的时间,说快也不算快,慢也不算慢,主要的时间都花在资源分类和搜索上。
算是第二个 React 项目了(第一个是该博客),不过由于该资源导航是纯静态的,没有任何与后端数据交互的,所以后续有空的话,应该是会写一个 ant-design-pro 后台管理模板,能与后端有数据交互的那种。至于后端技术栈的话,也许是 Node,也许是 Go 吧。